(1)
2013 年的 ImageNet 竞赛, 获胜的团队是来自纽约大学的研究生 Matt Zeiler, 其图像识别模型 top 5 的错误率, 降到了 11.5%.
Zeiler 的模型共有六千五百万个自由参数, 在 Nvidia 的GPU 上运行了整整十天才完成训练.
2014年, 竞赛第一名是来自牛津大学的 VGG 团队, top 5 错误率降到了 7.4%.
VGG的模型使用了十九层卷积神经网络, 一点四亿个自由参数, 在四个 Nvidia 的 GPU 上运行了将近三周才完成培训.
如何继续提高模型的识别能力? 是不断增加网络的深度和参数数目就可以简单解决的吗?
(2)
来自微软亚洲研究院的何恺明和孙健 (Jian Sun, 音译), 西安交通大学的张翔宇 (Xiangyu Zhang, 音译), 中国科技大学的任少庆 (Shaoqing Ren, 音译)四人的团队 MSRA (MicroSoft Research Asia),在2015 年十二月的 Imagenet 图像识别的竞赛中, 横空出世.

他们研究的第一个问题是,一个普通的神经网络,是不是简单地堆砌更多层神经元,就可以提高学习能力?
在研究一个图像识别的经典问题 CIFAR-10 的时候,他们发现一个 56层的简单神经网络,识别错误率反而高于一个20层的模型.
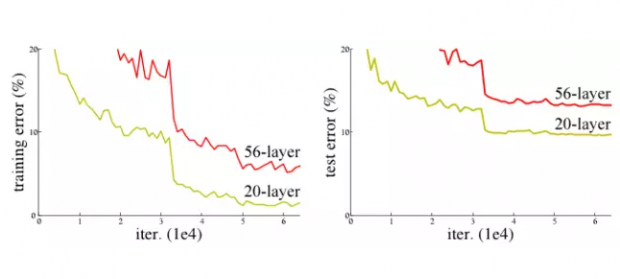
网络深度增加,学习的效率反而下降.为了解决有效信息在层层传递中衰减的问题, MSRA团队尝试了一种称为 "深度残余学习" (Deep Residual Learning) 的算法.
(3)
"深度残余学习"的概念, 借鉴了图像识别中的"残余向量"的概念.
本质上, 所谓'深度残余算法', 就是把神经网络一层层之间的非线性转换问题, 变成一个所谓的 "相对于本体的残余转换" (Residual mapping with respect to identity) 的问题,
实践上,使用所谓 "跳跃链接" (shortcut connection)的方法,把底层的输出值每隔几层跳跃直接传递成更高层的输入, 这样有效的信息不会在深层网络中被淹没.
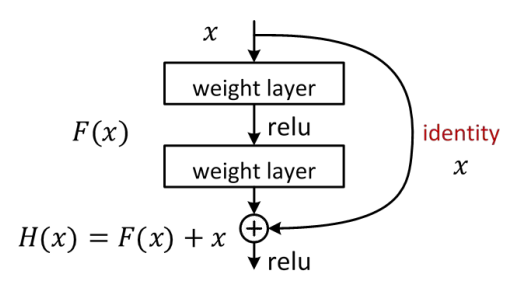
MSRA 的深度残余学习模型,使用了深达 152层的神经网络, top 5 的识别错误率创造了 3.57%的新低, 这个数字, 已经低于一个接受良好培训的正常人的大约 5% 的错误率.
更有意思的是, MSRA 计算模型的复杂度, 实际上还不到2014年获奖团队 VGG 的十九层神经网络的 60%.
(4)
几位研究者自己,都为这一个改进算法的神奇效果感到惊讶.这个模型,甚至连前几年极为流行的丢弃 (dropout) 算法, 都没有用上.
深度学习的现状,是理论基础远远落后于实践成果.新的成果往往来自各种大胆尝试.研究者可以发现有效的算法, 虽然自己也无法严谨地论证,有效性的根本原因.
今天领先的算法,可能没多久又被另外一个不同角度的解决方案完全超越.行业先行者多年经验的积累,很快就可能被新的进展变得过时.
这是一块浩瀚的处女地,等待着众多新生代的研究者去开拓.
即使在这样的初级阶段,深度学习在图像识别的问题上,2015年已经部分超越正常人的认知能力. 而机器仍然在不停地进步.
这对未来的深远影响, 有的人会觉得细思极恐. 但也有的人会是: 细思极乐.
(未完待续)


0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}