(1)
迄今为止我们讨论的神经网络模型, 都属于一种叫做前馈网络 (feedforward network) 的东西. 简而言之, 前馈网络, 信息从底层不断往前单向传输,故而得名.
RNN (Recurrent Neural Network), 也称循环神经网络, 多层反馈神经网络, 则是另一类非常重要的神经网络.
本质上, RNN 和前馈网络的区别是, 它可以保留一个内存状态的记忆, 来处理一个序列的输入, 这对手写字的识别, 语音识别和自然语言处理上, 尤为重要.
在分析一段语句时, 知道上文, 知道它前面的那些单词,非常关键. RNN 之所以叫 Recurrent (循环), 是因为对于一个序列的每个元素, 它都要做同样的处理, 通过一个内存原件记住当前状态, 然后将其引导回处理下一个元素的输入中.
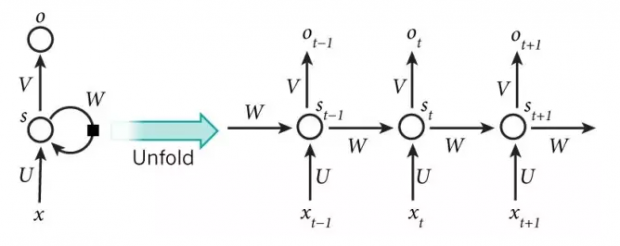
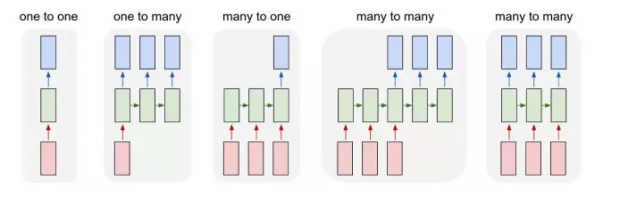
从另外一个角度看, 传统神经网络, 输入和输出的向量, 长度都是固定的, 是简单的一对一的关系.
而 RNN, 可以接受一个序列的输入向量, 输出也可能是一个序列, 二者是多对多的关系. 应用上, 它可以解决的问题广泛得多, 包括给图像生成字幕, 自然语言处理, 机器翻译,等等.
(2)
提到 RNN, 不可避免地要提到现在瑞士 Lugano 大学的 Jürgen Schmidhuber 教授.
1963年出生的 Schmidhuber, 和所有过早脱发的中年人一样, 外出时爱戴着一顶鸭舌帽.

1997年 Schmidhuber 和他的学生 Sepp Hochreiter 合作, 提出了 长短期记忆 (LSTM, Long Short-Term Memory) 的计算模型.
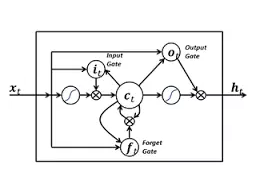
长短期记忆 (LSTM), 这个拗口的名字,背后要解决的问题, 是如何将有效信息, 在多层循环神经网络传递之后,仍能输送到需要的地方去.
LSTM 模块, 在神经网络里的角色, 是通过内在参数的设定 (如上图, input gate, output gate, forget gate),决定某个输入信息在很久以后是否还值得记住,何时取出使用, 何时废弃不用.
鲁迅在小说"藤野先生"里曾有这么一段文字: "那坐在后面发笑的是上学年不及格的留级学生,在校已经一年,掌故颇为熟悉的了。他们便给新生讲演每个教授的历史。这藤野先生,据说是穿衣服太模胡了 ... 有一回上火车去,致使管车 的疑心他是扒手,叫车里的客人大家小心些。 "
通俗的说, LSTM 就是这样一个机制, 好似"藤野先生"里面的"留级学生", 帮你管理很久之前的"掌故", 决定何时调用, 何时忽略.
如果"忘记历史意味着背叛", 那么对于没有使用 LSTM 的神经网络, "忘记历史则意味着迷茫和不知所措"。"深度残余学习", 本质上是借鉴了 LSTM 模型的思路, 但是去掉了里面的 forget gate (遗忘之门) 这个概念而已.
(3)
Schmidhuber 教授还是一位高段位的理论家和段子手. 从 1990年他就开始建立和完善他的关于"乐趣和创造力的正式理论" (Formal Theory of Fun and Creativity) , 试图从计算理论上,统一解释艺术, 音乐和幽默为什么会打动观众.
简而言之,Schmidhuber 认为, 人脑的认知之所以会觉得某个东西有趣,是因为他看到了一个新的以前不知道,但是又能够很快学习理解的东西. 如果完全都在预期之中, 那就枯燥无味; 如果太古怪, 大脑无法迅速识别理解,也不会有回报的快感.
公开场合, 他以此理论最爱讲的段子是:
"生物组织四大驱动力都是 F 开头: Feeding (吃), Fighting (斗), Fleeing (逃), Mating (交配) ". ( 这个段子的槽点在最后一个词. 本来听众的预期也是以 F 开头, 但是却看到了 M 开头的另外一个同义词. )
艺术, 音乐和幽默, 全在算法掌握之中,一个在新颖和相识间寻找平衡的算法.
艺术家, 作曲家和段子手们, 要感受 RNN 和 LSTM 的威力, 也许还要再过几年.
但在其它领域, LSTM 很早就开始发飙了.
(未完待续)


0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}