
(1)
循环神经网络 (RNN)的本质, 是可以处理一个长度变化的序列的输出和输入 (多对多). 广义的看, 如果传统的前馈神经网络做的事, 是对一个函数的优化 (比如图像识别). 那么循环神经网络做的事, 则是对一个程序的优化,应用空间宽阔得多.
长短期记忆 (LSTM)的架构, 使有用的历史信息, 可以保留下来,很久以后仍然可以读取.
一个有趣的应用, 是把大量文字作为输入培训 RNN, 让它掌握语言的规律, 自己也可以写文章了.
斯坦福大学的计算机博士 Andrej Kapathy 在他的博客中写道:
"有时我的模型的简单程度, 和高质量的输出相比,反差如此之大,远远超越我的预期".
(2)
Kapathy 使用了一种所谓的 "字母为基础的语言模型" (Character Based Language Model )来训练 RNN. 简而言之, 就是通过不断阅读大量文字, 让 RNN 自己可以较为准确地估计下面一个字母出现的几率. 当概率模型培训得慢慢成熟以后, RNN 就可以自己逐渐写出流畅通顺的文字.
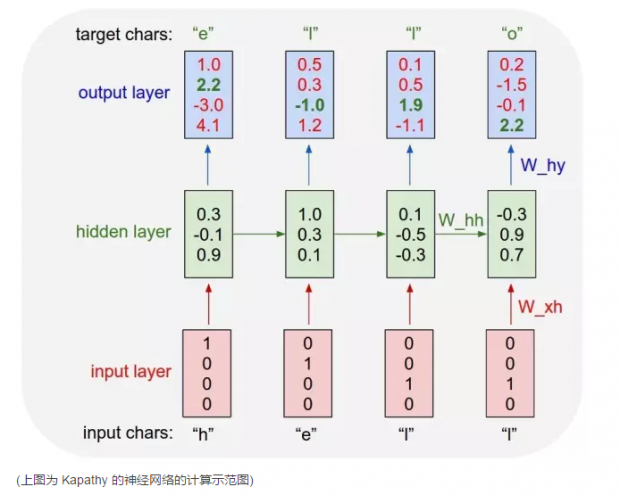
Kapathy 用托尔斯泰的小说 "战争与和平"来训练 RNN. 每训练一百个回合以后, 他让 RNN 输出一段自己创作的文字, 检查其学习效果.
100 回合: tyntd-iafhatawiaoihrdemot lytdws e ,tfti, astai f ogoh
机器知道要空格, 有时要逗号, 但是其它都是乱码
500 回合: we counter. He stutn co des. His stanted out one ofler that
现在知道大小写, 可以正确拼写一些短单词.
1200 回合: he repeated by her door. "But I would be done and quarts, feeling, then, son is people...."
可以使用复杂的标点符号, 较长的单词也可以拼写
2000 回合: "Why do what that day," replied Natasha, and wishing to himself the fact the princess, Princess Mary was easier,
可以正确拼写更复杂的语句.
从程序的演化过程看, 机器模型先领悟了单词之间的空格的结构, 然后慢慢认识了更多单词, 由短到长. 标点符号的规则也慢慢掌握. 一些有更多长期相关性的语句结构, 慢慢地, 也被机器掌握.
整个过程的最核心优点是, 没有人实现告诉程序, 具体的语法是什么,标点符号的规则是什么. 一切都是直接用原始数据训练, 时间长了,机器自己就慢慢发现单词, 空格, 引号和括号等等的规则.
自学习, 这就是人工智能, 让人神往的重要原因.
(3)
2016 年五月, 来自谷歌的 AI 实验室报道, 研究者用两千八百六十五部英文言情小说培训机器,让机器学习言情小说的叙事和用词风格.

机器在学习的过程中开始创作输出原创的文字, 有代表性的是下面这段:
“Her blouse sprang apart. He was assaulted with the sight of lots of pale creamy flesh bursting out of a hot pink bra "
(中文翻译: "她的上衣掀开, 他的视线遭到了一大片乳白色的从粉红文胸内喷薄而出的皮肤的攻击.")
琼瑶阿姨, 也许短期内还不用担心工作受到影响.
笔者小学三年级时, 曾有同班同学的作文写出不少令人捧腹的文字,一个典型的例子是:
"我秋高气爽, 凉风习习地走在荆江大堤上".
客观地说,谷歌程序的写作水准, 已经可以和小学三年级学生比肩.
但 AI 的最大优势, 是可以不断迅速地学习新的文字和数据, 而且这个能力在加速. 一本普通的两百页的小说, 其信息量大约在 0.6 个MB 上下. 三千部小说就是 1.8 GB, 在Nvidia 目前最新的 GPU上训练, 也不过就是几百个小时的事情.
文艺青年三毛在电影"滚滚红尘"主题歌中曾有作词: "终生的所有, 也不惜换取刹那阴阳的交流".
在 AI 的迅速进步面前, 这段歌词也许应该改为: "终生的所有, 也抵不上几百个小时的 GPU".
(未完待续)


0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}