(1)
影响 GPU运算速度的技术指标有好几个.
一般人讨论计算速度时, 大多在说芯片时钟的速度. 芯片频率越高, 时钟的一个周期越短, 速度越快. 但这只是计算能力中的一个维度.
集装箱船运的效率, 除了轮船航行的速度 (类似芯片的速度) 以外, 更重要的是轮船的吨位, 装卸货的时间, 港口等待的时间, 等等.
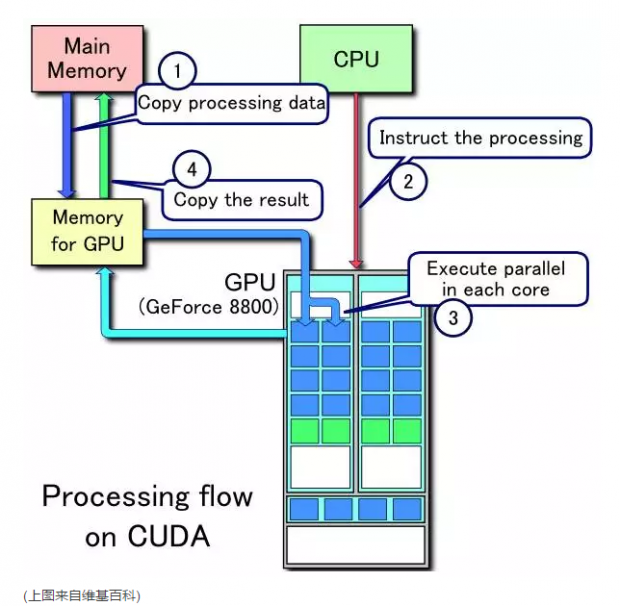
一个典型的计算流程是这样的:
1)数据从 CPU 的内存拷贝到 GPU 的内存.
2) CPU 把计算指令传送给 GPU
3) GPU 把计算任务分配到各个 CUDA core 并行处理
4) 计算结果写到 GPU 内存里, 再拷贝到 CPU 内存里.
除了时钟的速度, 衡量GPU计算能力的其它几个重要参数是:
1. (CUDA cores) 并行计算的核心处理器的数目. (类似轮船的吨位)
2. 内存大小 (类似港口的大小).
3. 内存带宽 (Bandwidth, 指数据传输的速度, 类似轮船装卸货的速度)
4. GPU/CPU之间通讯的带宽. (类似从港口到火车/卡车上的装卸货的速度)
任何一个技术参数过慢, 都可能成为妨碍计算能力进步的瓶颈.
反过来说, 提高计算能力的关键, 在于改进提高计算过程中的瓶颈.
(2)
2016年四月, 在硅谷的 GPU 开发者大会上, Nvidia 的黄仁勋宣布推出最新的超算系统 DGX-1. 这是一个拥有八个最新的代号 P100 的GPU的系统,售价接近十三万美元. 在运行 alexnet 的训练计算时间上, 只花费了两个小时, 比2012年十月 Alex Krizhevsky 团队使用两个 GTX 580 GPU, 六天的运算时间快了 75倍.

只需两个小时的训练时间,必然将推动更多精巧的算法被发现.
三年半快了 75 倍, 这个计算速度的提升, 是如何做到的呢?
P100 的时钟频率是 1328 Mhz, 比 GTX580 的时钟频率 1544 Mhz 实际上还略低一些. 但是:
第一, P100 有 3800 个core, 和 GTX 580 的 512个 core 相比, 并行程度增加了六倍以上.
第二, P100 的内存达到 16 GB, 是GTX 580的十倍以上. 内存带宽为 720 GB/s, 是 GTX 580 的三倍以上. (芯片的内存又细分为 Register/寄存器, Cache/缓存, Memory/内存, 这里暂不细表) 内存读写的瓶颈大大减小.
第三, P100 在硬件上实现了一些算法的直接支持,比如十六位的浮点数计算. 由于深度学习计算许多时候对精度要求并不高, 十六位浮点数的计算速度, 就比传统的三十二位浮点数计算速度快了两倍.
第四, 由于 P100使用了新的所谓 NVlink 的架构, GPU/CPU 直接通讯的带宽高达 160 GB/s, 是 GTX 580 的二十倍. GPU 之间数据传输, 不再是大的瓶颈. Nvidia 把八个 GPU 放在一起并行运算, 这和 2012年 Krizhevsky 团队使用两个 GPU 相比, 并行程度增加了四倍.
计算能力的提高,不再主要依靠芯片时钟速度的提高,而是通过提升不同模块之间的通讯带宽,加大并行程度而实现.
单兵作战能力不是主旋律, 大规模兵团的实时协同作战才是王道.
这可能是推动人类文明发展的最重要的洞见之一.
(3)
人类兵器史上, 从十八世纪一分钟可以射击不到十发的步枪, 到1883年一分钟射击六百发子弹的马克沁重机枪,这个技术跨越耗费了大约一百年. 而深度学习计算能力提高了七十五倍, 只花了三年半的时间.
即使我们假设使用两个P100 的GPU (而不是DGX-1 系统的八个), 和两个 GTX580 GPU对比,计算能力也增加了十八倍以上.
理解了驱动计算速度的重要因素后,很自然地就会引出下面三个问题:
第一, 按照最保守的估计,假设计算速度每四年加快十五倍,那么十四年左右就可以加快一万倍. 2013年谷歌有学者已经有使用两百亿个自由参数的模型, 那么最晚到 2027年, 应该就可以有两百万亿个自由参数的神经网络模型, 其复杂度和人脑在同一个量级上?
第二, 摩尔定律的进步, 在 GPU 内存容量, 内存带宽, 并行的核心处理器的数量增长上, 未来十几年内是否可以继续保持过去的增长速度, 进而支持至少计算速度增加一万倍以上的愿景?
第三, 如果你知道十几年后, 智能的爆发将等价于兵器史上从步枪, 到机枪, 到火箭炮, 到核弹的变化, 那么你现在是要花很多时间学习射击打炮, 还是更多的时间研究准备核武时代的新战略?
(未完待续)


0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}