(1)
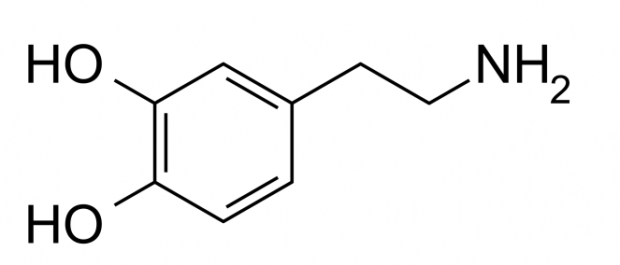
多巴胺,英文名 Dopamine, 是一种有机化合物, 学名 4-(2-Aminoethyl)benzene-1,2-diol, 4-(2-氨基乙基)-1,2-苯二酚, 在大脑中它的作用是在神经元之间传递信号的介质.
多巴胺作为神经介质 (neurotransmitter)的功能, 最早在1957年由瑞典化学家 Arvid Carlsson 发现, Carlsson 四十三年之后才因此发现获得诺贝尔奖.
多巴胺对于人脑的运作至关重要. 在普通人的印象中,多巴胺的释放是和食物,烟酒,性快感或者毒品联系在一起的.当人们获得各种快乐的奖励时,大脑释放大量多巴胺,让人们沉迷而无法自拔.
所以也有人称其多巴胺为"快感化学物" (pleasure chemical):快感/奖励, 导致多巴胺的释放.
(2)
早在 1901 年, 俄国科学家巴普洛夫发现一个有趣的现象: 通常狗在被喂食之前,会流口水. 但如果在给狗喂食之前,先摇摇铃铛,训练几次后,狗只要听到铃响,还没有看到食物时,就会马上开始流口水.

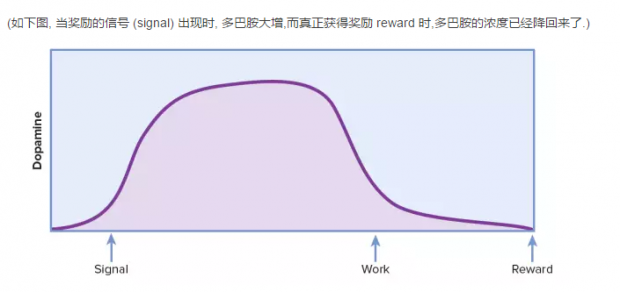
在一个实验中,科学家每次在老鼠吃东西之前,按响蜂鸣器. 训练几次后,只要一按蜂鸣器, 老鼠大脑的多巴胺浓度大增.真正吃到食物时,多巴胺的浓度又降下来了.类似的实验,在猴子身上也有相仿的结果.
多巴胺的释放, 来自对于奖励的预期,而不是奖励本身.
(3)
剑桥大学的Wolfram Schultz 博士在进一步研究中,有了新的发现.
对猴子大脑释放的多巴胺浓度的不断监测中,他发现如果猴子获得比预期更多的苹果汁,或者在没有预想到的时间喝到苹果汁,多巴胺分泌则大增.如果本来期待的苹果汁没有喝到,多巴胺的分泌大减.
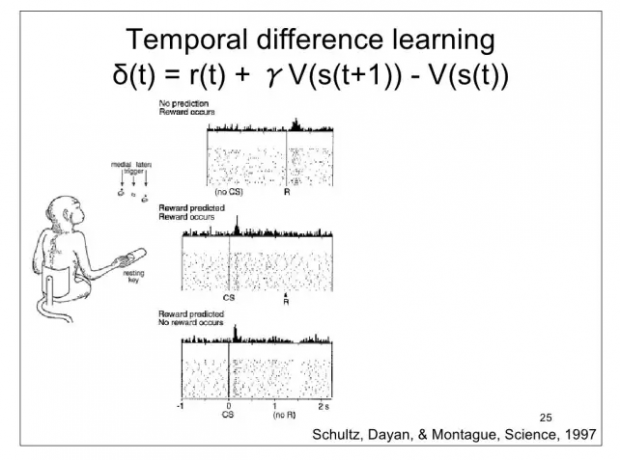
研究的结论是: 多巴胺的释放,取决于获得的奖励和预期之间的差值, Delta.
现实和预期的差别, 促成了多巴胺的释放, 这是学习和进步的源动力.
快乐,来自超越预期的惊喜和它带来的多巴胺释放.但如果没有新的花样超越大脑的预期,多巴胺浓度下降,生活趋于平静,这就是人们常说的夫妻之间的"七年之痒".如果短暂的分别降低了未来的期望值,那么重逢之后的多巴胺排放,如滔滔江水,这就是所谓的 "小别胜新婚"了.
关于多巴胺驱动大脑的机制,还有许多极为微妙复杂的细节, 此处暂不赘述.
(4)
时间差分学习 (Temporal Difference Learning, 下面简称为 TD学习) 思想的雏型, 上世纪五十年代就被不同的学者提出.
它的核心思想, 就是在每个时间点通过计算现实和预期的差值,来微调价值函数值. 这和大脑多巴胺释放的机制,不谋而合.
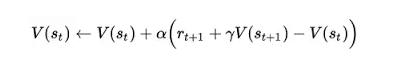
它和蒙特-卡洛(MC)模拟的区别在于, MC 模拟要在一个轮回之后,再更新各个节点的价值函数. 而 TD 是在每个时间点, 根据观察到的结果不断评估,微调.
打个简单的比方,如果把"过河"作为一个要解决的问题, 动态规划的解决办法,就是耗费大量时间测算河水的深浅,河里的石头大小,分布,然后计算最优的过河方案. 它的缺点是耗时过长, 很可能方案算出来的时候,你的孙子都已经出生了.
MC 模拟,就好比派一大群志愿者强行渡河,有些人在渡河中会摔跤甚至淹死,但经过大量先烈前赴后继的实验后,也可以找到最佳方案.
而TD 算法,就是"摸着石头过河".
当现实和预期存在差别时,有的人选择破口大骂,有的人选择视而不见/掩耳盗铃.而有的人则使用 TD 算法,根据这个差值, 实时的更新自己的世界观和策略. 使用 TD 算法的人,将会有更大的概率,在生存竞争中传递自己的基因.
TD 算法真正名声大噪, 要到 1992年, 在一个古老游戏上的应用.
(未完待续)


0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}