(1)
计算速度和数据规模的大幅度提高,也引导出更多算法上的改进.
在网络构架上,一些算法更多地借鉴人脑认知的成功经验: 多提高效率, 少做无用功. 多闭目养神,少乱说乱动. 多关注主要矛盾, 少关心细枝末节.
2003年纽约大学神经科学中心的 Peter Lennie 在论文中指出,人脑的神经元,一般最多 1-4%的比例, 可以同时处于激活状态. 比例更高时, 大脑则无法提供相应的能量需求.
神经网络的模型中,通过所谓激励函数 (activation function), 根据上一层神经元输入值来计算输出值.
最典型的传统激励函数,sigmoid function, 输出值在 0 和 1 之间, 也就意味着神经元平均下来, 每时每刻都在使用一半的力量.
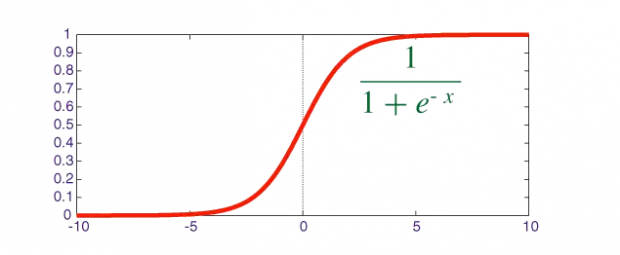
这种高强度能量需求,对于普通生物体而言,是无法持续的.
一个有意思的比方是鳄鱼.真实生活中的鳄鱼, 和动物世界的纪录片中纵身一跃, 凶猛捕食的形象大相径庭.
鳄鱼90%的时间是一动不动的, (一个近距离观察者常会把它误认为是石雕.) 剩下5%的时间用于求偶交配, 5%的时间用于觅食.

鳄鱼的低能耗绿色生活方式,使它成为两栖动物界的寿星.虽然野生鳄鱼的平均寿命缺乏严格科学的统计,但是被捕获后人工饲养的鳄鱼中,有不少个体,记录在案的寿命超过了七十岁.
(2)
2011 年, 加拿大的蒙特利尔大学学者 Xavier Glorot 和 Yoshua Bengio 发表论文, "Deep Sparse Rectifier Neural Networks". (深而稀疏的修正神经网络).
论文的算法中使用一种称为"修正线性单元" (REctified Linear Unit, 又称 RELU) 的激励函数. 用数学公式表达: rectifier (x) = max (0, x ).
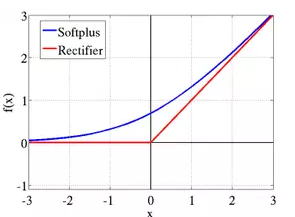
对于 RELU 而言, 如果输入为负值, 输出为零. 否则输入和输出相等.
换而言之,对于特定的输入, 统计上有一半神经元是没有反应,保持沉默的.
使用 RELU 的含有三个隐层的神经网络模型,被用来测试于四个不同的经典的图像识别问题. 和使用别的激励函数的模型相比, RELU 不仅识别错误率普遍更低,而且其有效性,对于神经网络是否进行"预先训练"过并不敏感.
RELU 的优势还有下面三点:
传统的激励函数,计算时要用指数或者三角函数,计算量要比简单的RELU 至少高两个数量级.
RELU 的导数是常数, 非零即一, 不存在传统激励函数在反向传播计算中的"梯度消失问题".
由于统计上,约一半的神经元在计算过程中输出为零,使用 RELU 的模型计算效率更高,而且自然而然的形成了所谓 "稀疏表征" (sparse representation), 用少量的神经元可以高效, 灵活,稳健地表达抽象复杂的概念.
(未完待续)


0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}