(1)
2016 年一月底,人工智能的研究领域,发生了两件大事。
先是一月二十四号,MIT 的教授,人工智能研究的先驱者,Marvin Minsky 去世,享年89岁。
三天之后,谷歌在自然杂志上正式公开发表论文,宣布其以深度学习技术为基础的电脑程序 AlphaGo,在2015年十月,连续五局击败欧洲冠军职业二段樊辉。
这是第一次机器击败职业围棋选手。距离97年IBM电脑击败国际象棋世界冠军,一晃近二十年了。
极具讽刺意义的是,Minsky 教授一直不看好深度学习的概念。他曾在1969年出版了 Perceptron (感知器) 一书,指出了神经网络技术 (就是深度学习的前身)的局限性。 这本书直接导致了神经网络研究的将近二十年的长期低潮。
神经网络研究的历史是怎样的?深度学习有多深?学了究竟有几分?
(2)
人工智能研究的方向之一,是以所谓 "专家系统" 为代表的,用大量 "如果-就" (If - Then) 规则定义的,自上而下的思路。
人工神经网络 ( Artifical Neural Network),标志着另外一种,自下而上的思路。
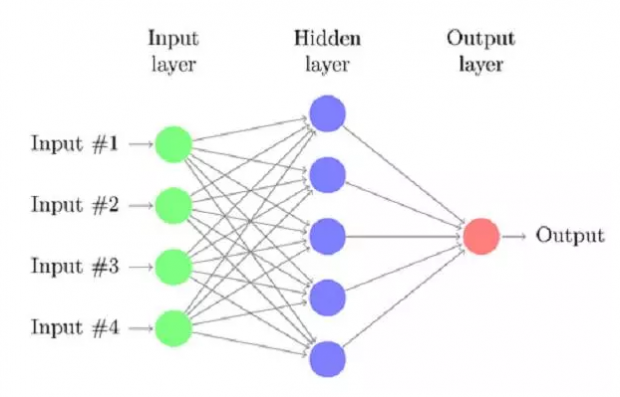
神经网络没有一个严格的正式定义。它的基本特点,是试图模仿大脑的神经元之间传递,处理信息的模式。
用小明、小红和隔壁老王们都可以听懂的语言来解释,神经网络算法的核心就是:
计算、 连接、评估、 纠错、疯狂培训
随着神经网络研究的不断变迁,其计算特点,和传统的生物神经元的连接模型渐渐脱钩。但是它保留的精髓是:非线性、分布式、并行计算、 自适应、自组织。
(3)
神经网络作为一个计算模型的理论,1943年最初由科学家 Warren McCulloch 和Walter Pitts 提出。
康内尔大学教授 Frank Rosenblatt 1957年提出的"感知器" (Perceptron),是第一个用算法来精确定义神经网络,第一个具有自组织自学习能力的数学模型,是日后许多新的神经网络模型的始祖。
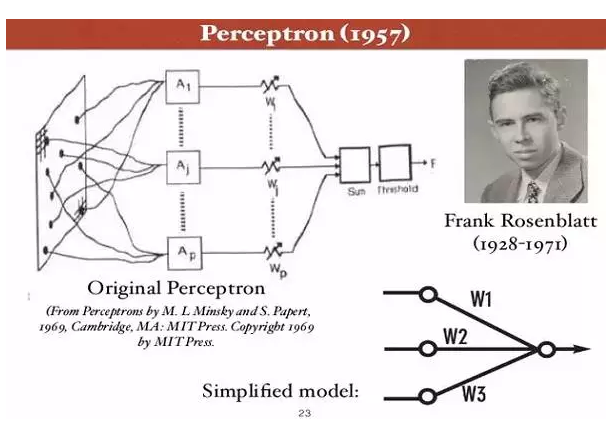
Rosenblatt 和 Minsky 实际上是间隔一级的高中校友。但是六十年代,两个人在感知器的问题上展开了长时间的激辩。Rosenblatt 认为感应器将无所不能, Minsky 则认为它应用有限。
1969 年,Marvin Minsky 和 Seymour Papert 出版了新书: “感知器: 计算几何简介”。书中论证了感知器模型的两个关键问题:
第一,单层的神经网络无法解决不可线性分割的问题。
第二, 更致命的问题是,当时的电脑完全没有能力完成神经网络模型所需要的超大的计算量。
此后的十几年,以神经网络为基础的人工智能研究进入低潮,相关项目长期无法得到政府经费支持,这段时间被称为业界的核冬天。
(4)
神经网络当年被 Minsky 诟病的问题之一是巨大的计算量。
1986年七月, Hinton 和 David Rumelhart 合作在自然杂志上发表论文, "Learning Representations by Back-propagating errors", 第一次系统简洁地阐述,反向传播算法在神经网络模型上的应用。
使用了反向传播算法的神经网络,在做诸如形状识别之类的简单工作时,效率比感知器大大提高。
八十年代末计算机的运行速度,也比二十年前高了几个数量级。
神经网络的研究开始复苏。
(5)
When in doubt, use brute force.
"如果遇到困惑(的问题),就使用蛮力。 "
此话出自当年 UNIX 系统的发明人之一 Ken Thompson。他的本意是,程序设计中简单粗暴的计算方法,虽然可能计算量大,但是便于实现和维护, 长期看还是优于一些精巧但是复杂的计算手段。
神经网络的研究, 呼唤着蛮力, 呼唤着来自计算速度,网络速度, 内存容量,数据规模各个方面的,更强大的指数增长的蛮力。
有哲人对蛮力有另外一个诠释: "Quantity is Quality"。
数量就是质量。 向数量要质量。
而这个蛮力的基础,其实在1993年就埋下了种子。

黄仁勋1993创立了 Nvidia 。Nvidia 起家时做的是图像处理的芯片,主要面对电脑游戏市场。1999年Nvidia推销自己的 Geforce 256 芯片时,发明了 GPU (Graphics Processing Unit, 图像处理器)这个名词。
GPU 在芯片层面的设计时,专门优化系统,用于处理大规模并行计算。
2007年 Nvidia 推出名叫 CUDA 的并行计算软件开发接口,使开发者可以更方便的使用其 GPU开发应用软件。多家大学的研究者撰文表示, 对于特定工作,NVIDIA GPU带来的相对于 Intel 的CPU 的计算速度提高, 达到 100-300 倍。
Intel 技术人员2010年专门发表文章驳斥,大意是 Nvidia 实际上只比 intel 快14倍,而不是传说中的100倍。
Nvidia 的 Andy Keane 评论: "老夫在芯片行业混了 26年了,从没见过一个竞争对手, 在重要的行业会议上站起来宣布, 你的技术 *** 只是 *** 比他们快14 倍"。
一个蛮力,一个来自 GPU 的计算蛮力,要在深度学习的应用中爆发了。
(6)
计算速度和数据规模的大幅度提高,也引导出更多算法上的改进。
2012年的夏天,距离 Hinton 教授 1970年开始攻读博士学位,距离 Rosenblatt 1971年溺水身亡, 一晃四十多年过去了。
深度学习的技术,此时有了:
1. GPU快捷的计算速度,
2. 海量的训练数据,
3. 更多新的聪明的算法.
条件已经成熟,该用实验结果,证明自己相对别的技术,无可辩驳的优越性了。
(7)
2009年,一群在普林斯顿大学计算机系的华人学者, (第一作者为 Jia Deng )发表了论文 "ImageNet: A large scale hierarchical image database),宣布建立了第一个超大型图像数据库,供计算机视觉研究者使用。

这个数据库建立之初,包含了三百二十万个图像。它的目的是要把英文里的八万个名词,每个词收集五百到一千个高清图片,存放到数据库里。最终达到五千万以上的图像。
2010年,以 ImageNet 为基础的大型图像识别竞赛,ImageNet Large Scale Visual Recognition Challenge 2010 (ILSVRC2010) 第一次举办。
2010年竞赛的第一名,是NEC 和伊利诺伊大学香槟分校的联合团队。用支持向量机 (SVM) 的技术,识别分类的错误率为 28% (计算机会对图像的分类,答出最有可能的头五个类别,所谓 top five category,如果正确答案都不在里面,即为错误)。
2011年竞赛的冠军,用所谓 Fisher Vector 的计算方法 (和支持向量机技术类似),将错误率降到了 25.7%。
Hintong 教授的团队, 使用了 两个 Nvidia 的 GTX 580 CPU (内存 3GB,计算速度 1.6 TFLOPS),让程序接受一百二十万个图像训练,花了接近六天时间。 经过训练的模型,面对十五万个测试图像时,预测的头五个类别的错误率只有 15.3%。在2012年 ImageNet 的竞赛,三十个团队的测试结果中,稳居第一。

排名第二的来自日本团队的模型,相应的错误率则高达 26.2%。所有其他团队采用的都是流行将近二十年的的支持向量机的技术。但是这一次,毫无疑义的,被神经网络的技术彻底超越了。
2012年十月十三日,当竞赛结果公布后,学术界沸腾了。
这是神经网络二十多年来,第一次,在图像识别领域,毫无疑义的、大幅度挫败了别的技术。
ImageNet 竞赛结果的公布,对于深度学习,对于人工智能,对于人类的未来,也许可用丘吉尔的一句话总结:
"这不是结尾。这连结尾的开头都算不上。 但, 这也许是,开头的结尾。"
(Now this is not the end. It is not even the beginning of the end. But it is, perhaps, the end of the beginning.)
(未完待续)


0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}