(1)
2012年十月, Geoffrey Hinton, 邓力和其他几位代表四个不同机构 (多伦多大学, 微软, 谷歌, IBM) 的研究者, 联合发表论文, "深度神经网络在语音识别的声学模型中的应用: 四个研究小组的共同观点" (Deep Neural Networks for Acoustic Modelling in Speech Recognition: The Shared Views of Four Research Groups ).
研究者们借用了Hinton 使用的"限制玻尔兹曼机" (RBM) 的算法 (这个系列的第四篇有介绍过), 对神经网络进行了"预培训". 深度神经网络模型 (DNN), 在这里, 替代了高斯混合模型 (GMM), 来估算识别文字的几率.
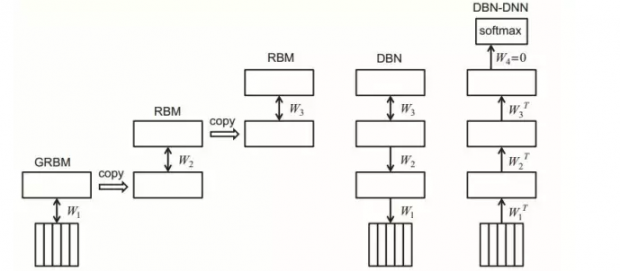
在许多不同的语音识别的基准测试里, 深度神经网络和隐形马尔科夫模型结合的 DNN-HMM 模型的表现, 全面超越了传统的 GMM-HMM模型, 有的时候错误率降低超过20%以上.
在谷歌的一个语音输入基准测试中,单词错误率 (Word Error Rate) 最低达到了 12.3%
谷歌的研究者 Jeff Dean 评价, "这是20年来,在语音识别领域, 最大的一次性进步. ".
(2)
迄今为止, 深度神经网络的引入, 只是部分地替代了高斯混合模型的统计算法. 其底层的语音识别,还是依靠"隐藏马尔科夫模型" (HMM) 的概率模型的架构.
传统的做法,是把声波拆分成大约十毫秒长的语音单元,用深度神经网络 (DNN) 来计算各种发音的概率分布, 然后再用 HMM 概率模型和其它语言模型的辅助工具, 来进行最终的语句识别.
HMM 最大的局限性, 在于其所谓的"有条件独立性 (conditionally independent)"的假设: 就是说, 系统在时间 t 的输出 y(t), 只在概率上依赖于隐藏马尔科夫序列上当前的元素 x(t), 而和别的时间点上的元素完全独立,没有关系.
但对于复杂的语音识别, 尤其是较长的语句, 上下文之间的关联是非常重要的.
举个简单的例子, 如果一个人说 "我在法国长大.. 我说一口流利的 (哪国的语言?) ". 如果要让机器准确预测最后一个词, 是什么语言的话, 对于语境的记忆至关重要. 机器需要记得,在前面几句话里,说话人提到他在哪个国家长大. 简单的 HMM 模型, 处理这类语境问题, 显然不够.
要进一步提高,需要藤野先生班上的那些"掌故颇为熟悉的留级生", 该 RNN/LSTM 粉墨登场了.
(3)
2013年三月, 多伦多大学的 Alex Graves 领衔发表论文, "深度循环神经网络用于语音识别" (Speech Recognition with Recurrent Neural Network). 论文中使用 RNN/LSTM 的技术, 一个包含三个隐层, 四百三十万个自由参数的网络, 在一个叫做 TIMIT 的基准测试中, 所谓的"音位错误率"达到 17.7%, 优于同期的其它所有技术的表现水准.
2015年五月, 谷歌宣布, 依靠 RNN/LSTM 相关的技术, 谷歌语音 (Google Voice) 的单词错误率降到了8% (正常人大约 4%).
2015年十二月, 百度 AI 实验室的 Dario Amodei 领衔发表论文, "英语和汉语的端对端的语音识别". (之所以叫端对端, 是指一个模块就可以解决整个问题, 不需要多个模块和太多人工干预.)
论文的模型, 使用的是 LSTM 的一个简化的变种, 叫做"封闭循环单元" (Gated Recurrent Unit).
百度的英文语音识别系统, 接受了将近一万两千小时的语音训练, 在 16个GPU上完成训练需要 3-5 天.
在一个叫 WSJ Eval'92 的基准测试中, 其单词错误率达到3.1%, 已经超过正常人的识别能力 (5%). 在另外一个小型汉语基准测试中, 机器的识别错误率只有3.7%, 而一个五人小组的集体识别错误率则为4%.
按照这个趋势, 机器在语音识别的各种基准测试上的准确度, 很快将全面赶上并且超过普通人了. 这是在图像识别之后, 人工智能即将攻克的另一个难关.
百度的吴恩达这样说, "许多人不理解准确度在 95% 和 99% 之间的差异. 99%将改变游戏规则.当你有 99%的正确率时, 用户的体验不会有(明显)损害".
好玩的东西才刚刚开始, RNN/LSTM 很快被程序猿们开发出新的应用.
(未完待续)


0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}