(1)
解决CPU 时钟瓶颈问题的另外一个维度,是增加系统的并行度,同时多做一些事情.
传统上,一个CPU 的芯片只有一个处理器(core, 也称内核 或 核心),当单个 CPU 的时钟速度很难再提高时,芯片设计者的另外一个思路是: 在同一个芯片上增加新的内核,让多个内核同时并行处理一些计算工作.
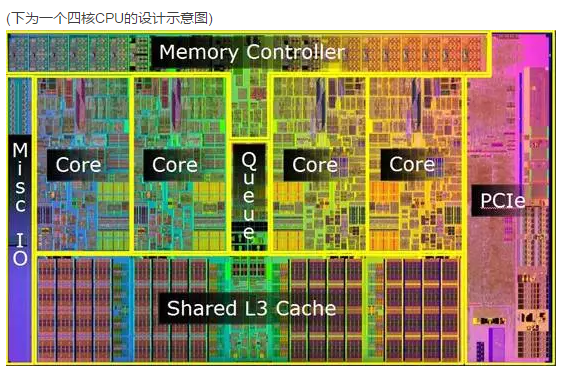
多核 CPU 的第一个好处是节能. 前面提到,处理器的能耗大约和时钟的频率的三次方成正比. 理论上说,如果把一个内核的时钟频率降低一半 (运算速度也降低一半),能耗就只有原来的八分之一.
如果要解决的计算任务可以很容易分成两部分,并行处理,那么一个双核的CPU可以在保持同样计算能力的情况下,通过降低内核时钟频率的办法,把整体功耗降为原来的八分之一.
当然,这只是理论上的最佳情况, 影响实际功耗的因素,比这个复杂得多.
(2)
但是 -- 许多应用问题运行上有各类瓶颈,无法充分利用并行计算,尤其是普通个人电脑上的应用. 反对者常常引用的一个例子是"一个女人要九个月才可以生一个孩子,但是你无法让九个女人一个月生一个孩子".
所有的"但是"后面,往往还有另外一个"但是".如果目标是一个月内生出一个孩子,这个问题确实无法通过并行化加快.但是 -- 如果目标是九个月内尽可能生更多的孩子,这个问题完全是可以通过九个女人并行化实现!
从一个新的角度,改变原来设定的目标,就会给现有的技术方法找到用武之地.这个原则,在设计并行计算的系统,在思考解决其它问题时,特别需要注意的一点.
如果说,普通个人电脑要关注的,是生一个孩子的问题. 那么,超级计算机,要解决的,就是在九个月内生最多数目孩子的问题.
2016年四月出品的售价十三万美元, 功耗三千瓦, 包含三万多个内核的 Nvidia 的 DGX-1 系统, 计算速度已经达到约 43 TFLOPS. (当然, CPU/GPU/不同系统的内核,性能特点不一样,有时不可简单类比,在此不赘述.)
到了 2016年, 排名世界第一的超级计算机, 是无锡的神威太湖之光, 包含一千万个内核, 成本接近三亿美元,耗电十五兆瓦,而计算速度则达到 93000 TFLOPS, 是 ASCI White 的一万三千百倍左右.

ASCI White 当年的处理器内核,时钟频率只有 375 Mhz. 而太湖之光的内核,时钟频率大约 1.45 Ghz. 内核的频率相比, 十六年增加了大约四倍.
但以内核数目来衡量的并行程度,则增加了一千两百倍.
这也是过去十几年,超级计算机,计算能力进步的最主要动力.
(3)
为什么新一代的超级计算机, 可以支持如此大型的并行计算能力? 而以前做不到?
这要归功于新一代的网络交换器 (Network switch)的数据传输速率, 让不同的内核之间, 系统节点之间, 可以迅速沟通,传输海量数据.
给神威提供交换机芯片的公司, 是总部位于硅谷和以色列的 Mellanox 公司. 神威系统的对分网络带宽高达 70 TB/秒, 这个数字是普通家庭宽带上网带宽的几百万倍.

交换器数据传输速率的进步,又要归功于摩尔定律下的晶体管的不断小型化.
(未完待续)


0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}