
(1)
迄今为止我们讨论的人工智能的问题,都还是局限在"认知"方面的应用, 比如图像识别,语音识别,自然语言处理,等等.
这类问题的特点是,机器获得大量原始数据的培训. 每一个输入,都有标准的"输出"的答案. 这种学习方式,也称为"有监督学习".
但是生活中大多数问题,是没有标准正确答案的.你的所作所为,偶尔会得到一些时而清晰, 时而模糊的反馈信号. 这就是"增强学习" (Reinforcement Learning) 要解决的问题.
"增强学习"的计算模型,最核心的有三个部分:
1. 状态 (State): 一组当前状态的变量 (是否吃饱穿暖, 心满意足? 是郁郁寡欢, 还是志得意满? )
2. 行动 (Action): 一组可以采取的行动变量 (是努力工作, 还是游山玩水? 是修身养性, 还是夜夜笙歌? )
3. 回报 (Reward): 采取行动, 状态改变后,把当前获得的回报定量化. (喝酒就脸红, 吃多了就发胖, 大怒就伤肝, 工作超过八个小时身体就被掏空, 等等).
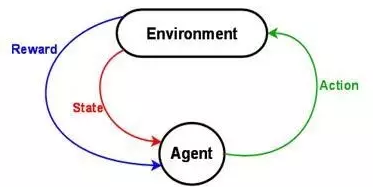
增强学习的最终目的,就是在和外界环境的接触/探索/观察的过程中,不断改进策略,把长期的回报/利益最大化而已.
(2)
增强学习的理论基础, 要从运筹学里的"贪婪算法" (Greedy Algorithm) 说起.
什么是贪婪算法? 简单说,就是,任何时候的决策,都是选择当前观察的最优解,而没有整体长远的规划.
贪婪算法的优点是容易理解,简单快速.但缺点是,得到的往往是局部最优解,而不是全球最优.
在子女教育中,"不要让孩子输在起跑线上"就是一种典型的贪婪算法的思维.那些放弃自己的努力,而把希望寄托在下一代的家长们,处心积虑地寻求当前最优解. 他们把孩子推送到重点幼儿园,重点小学,重点中学,重点大学,让各种小提琴/钢琴/奥林匹克数学培训班占用孩子的业余时间,生怕孩子看上去比别人落后一点点.
但是学校教授的技能和社会需求变化往往存在严重脱节,同时大多数孩子缺乏对挫折和压力的灵活应对的训练. 当孩子从学校出来走向社会时,巨大的落差导致的各种不适应和问题就出现了.
郭德纲老师在一次访谈中,深刻地指出, "吃亏要趁早,一帆风顺不是好事. 从小娇生惯养,没人跟他说过什么话,六十五岁走街上谁瞪他一眼当时就猝死".
这就是对"贪婪算法"在儿童教育上的局限性的最无情犀利的鞭挞.

(3)
动态规划,英文是 Dynamic Programming, 直译为"动态程序", 这个概念由美国数学家 Richard Bellman 在1950年提出. 它是在贪婪算法的基础上改进的算法. 实际上它和"动态","程序"两个概念没啥关系.
据 Bellman 老师介绍,当初为了忽悠政府的经费,就使用了"动态"这个词.动态,给人一种灵活,性感,高大上的感觉.谁会对"动态"说不?
动态规划算法的本质,是把一个复杂的问题拆分为多个子问题,并且把子问题的答案存储起来,避免以后的重复计算.

由于动态规划是从全局分析问题,所以往往可以找到全局最优解.但它的局限是,
第一, 计算量大,需要穷举和存储子问题的解答方案.
第二,动态规划的隐藏的假设是一个叫做"最优化原理"的东西,就是说,最优化的解决方案,可以通过其子问题的最优解决方案获得. 换句话说,最优化问题的子决策,对于相应的子问题也是最优的.
什么样的问题不符合"最优化原理"?
一个典型的反例, 从点 A 到 点 B 的机票,最便宜的路线选择,是要到点 C 转机. 但从 A 到 C 最便宜的机票 (子问题), 却要从 点 D 再转机.
(未完待续)


0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}