(1)
动态规划理论的核心, 用以 Richard Bellman 老师名字命名的 贝尔曼方程 (Bellman Equation)表示.
贝尔曼方程的核心, 就是:
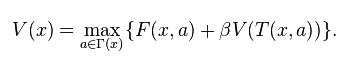
用大白话说, 就是
目前状态的最大价值 = 最大化[ 眼前的回报 + {未来的最大价值,贴现到现在} ]
而动态规划要解决的问题,无非就是求解方程里的最优价值函数 V(x) 而已.
使用贪婪算法的人们,只专注"眼前的回报",而忽略了"对未来最大价值贴现到现在"的认真计算.
社会上对部分大学生贴上的标签,"精致的利己主义者",实际上应当看成是"努力求解贝尔曼方程的人们".
没有损害他人利益的"利己和精致", 不仅无可厚非, 更须理直气壮. 但求解最优价值函数, 真正做到精致,那可不是喝几碗心灵鸡汤就可以达到的, 谈何容易!
(2)
动态规划在实际操作上,最大的挑战就是所谓 "维度的诅咒" (Curse of Dimensionality),就是随着变量的增加,问题的复杂度和计算量的需求,指数倍地增长.
"维度的诅咒", 主要包含了三个维度:
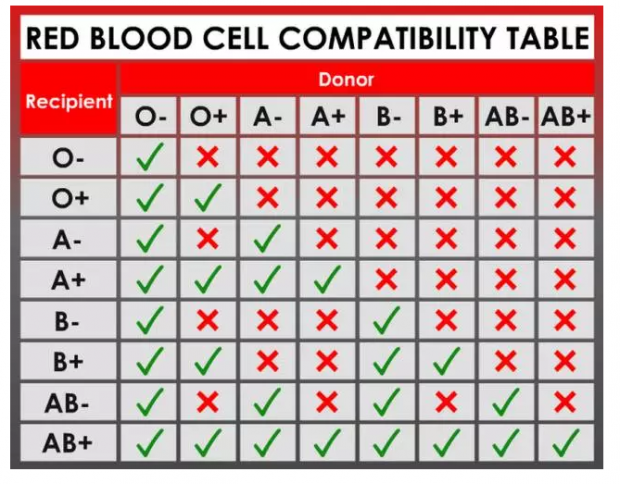
一, 状态空间 (state space): 举个简单的例子, 医院的血液库管理中, 主要有八个不同类别的血型 (A+, A-, B+, B-, AB+, AB-, O+, O-), 而这些血液的存量数量从 0, 1, 到 M不等. 那么这个状态空间就有 M^8 种可能.
二, 结果空间 (outcome space): 还是以血液库的管理为例, 每周都有不同数量的不同血型的血液,被捐献或者输出.
三, 行为空间 (action space: ): 不同血型之间, 谁可以给谁输血,有几十种可能性.再加上血液库里每个血型的不同存量数目,行为空间之广阔,让人头大.
再回到子女教育的例子,状态空间,结果空间和行为空间更是浩瀚无垠:
小孩送到那个重点托儿所? 重点小学? 重点中学? 要参加哪些才艺培训班和竞赛? 哪个班的老师名声最好? 要给哪些老师塞多少红包? 孩子的表现是否可以在朋友面前满足我的虚荣心?
大学学什么专业? 毕业后是工作,出国还是读研究生? 是考公务员还是去民企,国企? 哪个职业钱多事少离家近?
如何让小孩娶(嫁)得最好? 孩子的对象是否门当户对, 能赚钱,又听话孝顺? 孩子什么时候再生孩子?...
(3)
如果计算量太大,无法精致,那么退而求其次,我们就寻求"近似精致".
一个近似精致的解决思路,是所谓"蒙特卡洛模拟" (Monte-Carlo Simulation).
MC 模拟优化的核心, 分两个部分:
第一是计算模拟. 当没有简单的理论模型,维度的诅咒无法逾越时,取而代之的是用计算机随机产生的参数,对可能的路径发展进行大规模模拟计算. 大量模拟之后,在各个状态节点,根据其模拟的平均值, 计算出一个接近理论值的预期价值函数.
第二是通用策略迭代 (Generalized Policy Iteration), 根据模拟出来的价值函数,使用贪婪算法修正各个状态的策略,也就是说,修正后的策略在每一步的选择,都是根据模拟的价值函数,寻求下一步的眼前利益最大化. 再根据调整的策略,回到第一步, 重新模拟,更新价值函数.
两个步骤不断循环,渐进提高,直到接近最优值.
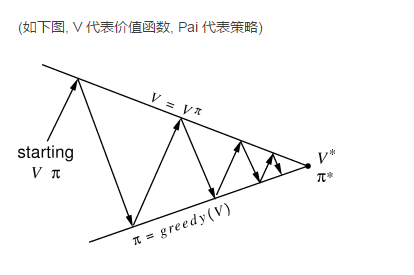
关于 "通用策略迭代", 一个生活中的例子是,八十年代的宣传是"学好数理化,走遍天下都不怕",所以数理专业是当时大学生短期利益最大化的最优选择.
但数学物理毕业生大多很难找到好工作,读 MBA 才可以有最高的薪水,许多人又纷纷跑去读 MBA. 拿到 MBA, 到大公司工作几年后,遇上金融危机,没攒什么钱又可能被解雇了. 过了几年再发现,有些刚毕业就去开公司的小毛孩,身价已经估值过亿.于是再改头换面,加入新的创业大潮.
(4)
MC 模拟的一个优点是,无须建模,完全根据实际经验来学习,容易上手.
毛主席曾说:“一些老粗能办大事。成吉思汗,是一个不识字的老粗。刘邦,也不认识几个字,是老粗。朱元璋也不认识字,是个放牛的。… ** 没念过书, ** 也没有念过书,** 念过高小, 结论是老粗打败黄埔生。”
这里的老粗,就像大量 MC模拟后的生成的实用性强的算法,没有生硬的理论培训,就在枪林弹雨中不断被淘汰,被选择,被教育. 而黄埔生则是被"维度的诅咒"束缚的动态规划的理论.
但 MC 模拟算法的一个不足是, 学习和提高 (根据价值函数,更新策略) 是要在一个模拟的轮回, 岁月蹉跎之后才可以发生,而不能够实时进行.
在残酷的生存竞争中,需要的是,一种更快的, 根据反馈来实时调整策略的能力.
这个算法的改进,启发来自于人脑多巴胺 (Dopamine)释放的机制.
(未完待续)


0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}