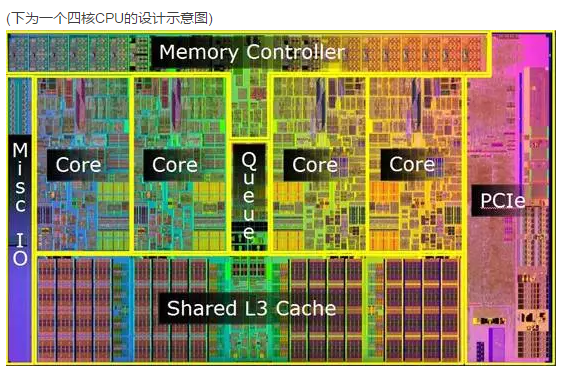
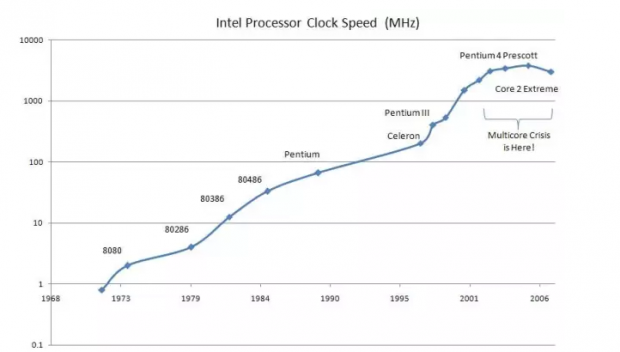
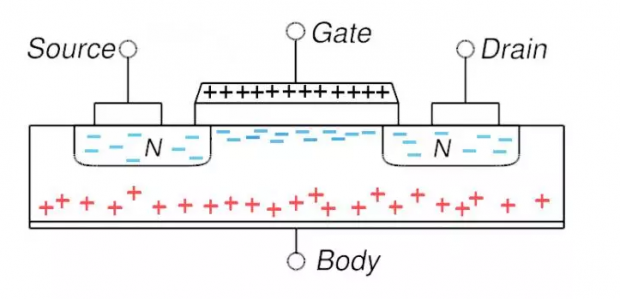
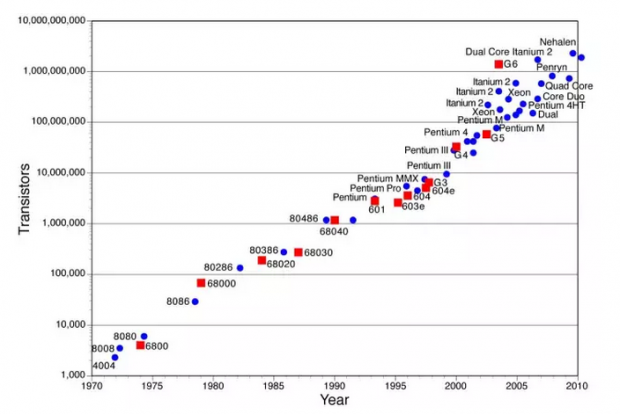
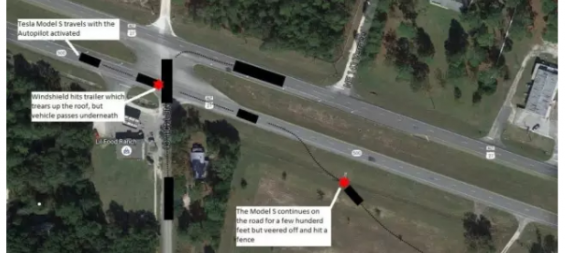
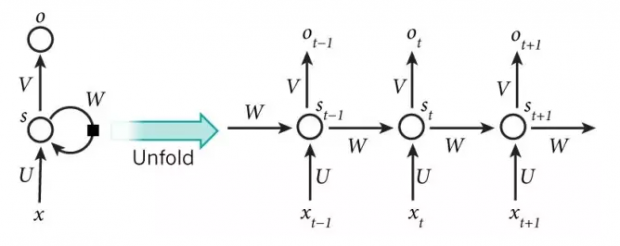
摩尔定律还能走多远(六)有钱能使鬼推摩(尔定律)

(1)
2012年七月,半导体制造业发生了一件大事: 三家芯片生产的巨头,英特尔/台积电/三星, 集体为半导体光刻业的巨头, 荷兰公司艾司摩尔 (ASML), 承诺支付累计十三亿欧元的研发费用,帮其承担部分新技术开发的风险.
三家公司同时还以每股接近 40 欧元的价格注资购买了 ASML 大约23%的股票. ( 四年后的2016年七月, ASML 股价在 96 欧元左右.)
ASML 获得的资金, 主要用于加快 450 毫米晶圆片相关的器材和下一代极紫外线光刻技术 (...