从有限游戏和无限游戏看连续性
1/ 纽约大学学者 James Carse 在 1986年出版的 "Finite & Infinite Game" 中,详细阐述了有限游戏和无限游戏的区别。 2/ 有限游戏是有明确胜负定义的游戏, 是一种有较为清晰的边界,时间长度和规则的游戏 ;有限游戏里,任何让你离最终胜利更近的行动,会被认为是好的行动。应试教育,体育比赛,政治竞选,某个大奖,首富的排行榜等等,都可以看成是有限游戏。 3/ 有限游戏的赢家,往往会得到多数人公认的某个头衔...
1/ 纽约大学学者 James Carse 在 1986年出版的 "Finite & Infinite Game" 中,详细阐述了有限游戏和无限游戏的区别。 2/ 有限游戏是有明确胜负定义的游戏, 是一种有较为清晰的边界,时间长度和规则的游戏 ;有限游戏里,任何让你离最终胜利更近的行动,会被认为是好的行动。应试教育,体育比赛,政治竞选,某个大奖,首富的排行榜等等,都可以看成是有限游戏。 3/ 有限游戏的赢家,往往会得到多数人公认的某个头衔...
1/ 在推特上看到一些资深程序员回顾过去三十多年编程技术的变迁,非常有借鉴意义。 2/ 有人说,在 1988年看,有三样技能对于程序员来说最重要。 C 语言, 图形界面编程, 面向对象编程。 3/ 但没有人预测到 1993年浏览器的出现。 1995年之后, 市场上对于会用 HTML编程,会维护 apache server, 会写 CGI 程序的需求大增。 实践中 Perl 和 Python 也是最常用的工具。 Perl 实际上比 Python 更流行。 ...
1/ 奋斗中的人们会有一个幻觉,就是美好的未来,对自己是连续的:换言之,人们会认为,只要自己不断努力埋头干,攒的钱越多,就越接近美好的未来。 2/ 但实际情况并非如此,原因主要有二: 第一,很多行业可能会突然出现向上的爆发式增长,和向下的迅速彤塌, 这两种情况都是不连续的。 错过前者,或者撞上后者,都会有巨大的差别。 3/ 第二,从风险管理角度看,即使统计上有看似极大的回报,但是如果某个行为方...
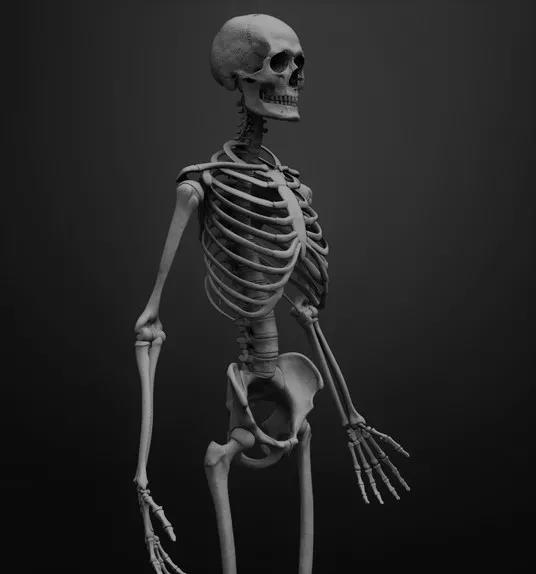
(本文系原创科幻小说,如果人名、地名和故事情节有雷同,纯属巧合,请勿自作多情,对号入座。) (13) “这是我们最新生产的样品,耳机端口的芯片会自动伸展到内耳,和里面的脑神经建立连接”。杰夫递给我一副耳机。 我把耳机带好后,内耳深处传来一种不可名状的怪异的感觉,不禁哆嗦了一下,几秒钟后才镇静下来。 “看到你面前这个骷髅骨架吗?你的大脑现在已经通过无线信号和它连为一体,但是...

(提示:作者持有特斯拉股份,以下个人观点仅供参考,不构成对所述资产投资建议,投资有风险,入市须谨慎。)
(1) 笔者在八月初写过一篇关于 特斯拉私有化的文章。 本来以为这个事基本就完了,盖棺定论了。没想到半个月之后特斯拉宣布不再继续私有化,然后因为此事的流产,又生出新的幺蛾子。因为马斯克在市场交易期间公开发推,被美国证监会起诉,导致股价一度大跌。 十月初甚至有在纽约的朋友问...当今创业,尤其是互联网创业,主要的思路是拼价格,忍住亏损,烧很多钱迅速造成规模效应,争取一家独大,最后才考虑盈利。有极少数创业者走这条路成功,以至于这种思路已经成为主流,把它默认为唯一正确的创业思路。 残酷的现实是,大部分走这条路的创业者,无法成功。不仅自己损失大量金钱,而且长期熬夜工作对身体造成严重损害,极个别的人甚至三四十岁就猝死。 Dan Lok 是一个出生在香港,现在居住在温哥华的八...

(本文系原创科幻小说,如果人名,地名和故事情节有雷同,纯属巧合,勿自作多情,对号入座。) (11) 漆黑的房间,伸手不见五指,我只能根据听觉努力判断那个东西的方位。 突然,一束强光投射到房间的墙壁上,开始放起电影来。电影中男子的对白,感觉非常熟悉。 "I have an M.D. from Harvard, I am board certified in cardio-thoracic medicine and trauma surgery, I have been awarded citations from seve...
 (本文系原创科幻小说,如果人名、地名和故事情节有雷同,纯属巧合。请勿自作多情,对号入座)
(9) 晚餐结束后,我送小驴去机场,他要搭乘当晚的红眼班机回东部。 “老王,你还记得前几年那部讲哥伦比亚毒枭 Pablo Escobar 的连续剧吗? ” “记得,怎么了?” “Escobar 说,You got to have vision, 你一定要有开阔的视野. 所以他们从哥伦比亚的小天地转战到迈阿密的大市场,产品单价和客户数...
(本文系原创科幻小说,如果人名、地名和故事情节有雷同,纯属巧合。请勿自作多情,对号入座)
(9) 晚餐结束后,我送小驴去机场,他要搭乘当晚的红眼班机回东部。 “老王,你还记得前几年那部讲哥伦比亚毒枭 Pablo Escobar 的连续剧吗? ” “记得,怎么了?” “Escobar 说,You got to have vision, 你一定要有开阔的视野. 所以他们从哥伦比亚的小天地转战到迈阿密的大市场,产品单价和客户数...
 (本文系原创科幻小说,如果人名,地名和故事情节有雷同,纯属巧合. 请勿自作多情,对号入座)
(7) “ 找人测试有什么问题?不是有那么多病人吗?” 我不解地问道. “喔,那问题可多了。首先你要找到很多病人愿意随叫随到配合你的实验,他要愿意让你在头盖骨上钻个小洞,在顶上植入芯片 ; 第二,没有人知道实验过程中病人是否会突然感染细菌或者病毒,甚至出现生命危险;病人的看护费用可比猴子昂贵多了;我们无法彻底...
(本文系原创科幻小说,如果人名,地名和故事情节有雷同,纯属巧合. 请勿自作多情,对号入座)
(7) “ 找人测试有什么问题?不是有那么多病人吗?” 我不解地问道. “喔,那问题可多了。首先你要找到很多病人愿意随叫随到配合你的实验,他要愿意让你在头盖骨上钻个小洞,在顶上植入芯片 ; 第二,没有人知道实验过程中病人是否会突然感染细菌或者病毒,甚至出现生命危险;病人的看护费用可比猴子昂贵多了;我们无法彻底...
(本文系虚构科幻小说,如果人名,地名和故事情节有雷同,纯属巧合. 请勿自作多情,对号入座) (5) 会议结束,我和小驴在海边的餐厅继续吹牛聊天,畅谈人生。 “小驴,我真是佩服你啊,这么多年来可以坐得住,一直潜心攀登科学高峰。不像我们这种俗人,只对吃喝玩乐感兴趣”, 我感叹道。 “哈哈,老夫没你想的那么高大上,这一切都是一个蓄谋已久的游戏而已。你说说,为什么人会对吃喝玩乐感...
 1/ 七零后可能都会记得,八十年代的初中英文课本,描绘未来世界里会出现一种“可视电话” (vision phone), 打电话同时还可以看到对方的面容。当时课本里还专门有个故事,里面的小男孩通过 vision phone 和医生谈话,并且用它订购了一辆十速自行车 (10-speed bicycle) 2/ 可视电话从 1870年电话出现之后,就一直成为技术人员追求的梦想。真正的研发从上世纪二十年代开始,就不断有各种尝试。最初是把两个远距离的闭路电视系...
1/ 七零后可能都会记得,八十年代的初中英文课本,描绘未来世界里会出现一种“可视电话” (vision phone), 打电话同时还可以看到对方的面容。当时课本里还专门有个故事,里面的小男孩通过 vision phone 和医生谈话,并且用它订购了一辆十速自行车 (10-speed bicycle) 2/ 可视电话从 1870年电话出现之后,就一直成为技术人员追求的梦想。真正的研发从上世纪二十年代开始,就不断有各种尝试。最初是把两个远距离的闭路电视系...
(1)
今天 (硅谷时间八月七号)马斯克宣布计划以 420 美元一股的价格私有化特斯拉。
特斯拉股价收盘在 379.5 美元,接近历史最高点。
特斯拉的收盘市值也已经达到约六百四十五亿美元, 超过了宝马的五百九十亿美元的市值。
笔者在 2016年十月曾在文章“2018年是汽车工业的大转型时刻(二)”里,预测过 Model 3 对宝马,奔驰,雷克萨斯等豪华车的冲击。
看到过去的预测正在一步步接近现实,恨不得从肩膀上伸出...
1/ 大部分人无法发财,最主要的原因,是自己做的事很容易被替代。
2/ 学的东西 (输入) 和 做的东西 (输出) 和别人一样,没有什么独到和与众不同的东西。 这就过滤掉 99.9 %的人 了.
3/ 即使有独到的东西,还需要大规模宣传,建立自己的品牌和一定规模的共识。这又过滤掉 99%的人了。
4/ 有独特的东西和有品牌之后,还有关键一步:需要有意识去控制供给,制造稀缺性,实践稀缺性溢价的艺术,把利润最大化...
1/ 涌现的经典定义为,在复杂系统内,不同元素的连接,产生了“整体 (远大于)>> 局部之简单叠加” 的现象。
2/ 氨基酸是涌现, DNA 是涌现, 原核/真核细胞是涌现,大脑是涌现,部落/城邦/国家都是涌现。
3/ 容易催生涌现的客观条件是:
外界的巨大能量输入 ;
不同元素之间的连接成本极低,接近于零。
连接迟滞极低, 连接带宽(数据传输速率)极高.
巨大数量的元素发生连接。
...