从抄袭的进化优势看强者益强(一)
 (1) 到陌生都市的游客,驻足街头寻找餐馆时,常常面临这样一个问题: 一家餐馆人满为患,热闹非凡; 隔壁另一家餐馆门可罗雀,只有两三个食客. 在没有其它更多信息的情况下,该到哪家餐馆吃? 如果你像大多数人一样, 答案是: 选择那家人多的餐馆. 因为你没有能力迅速判断哪家餐馆更好,而其他人的选择,成了最可靠的指南. 这种行为模式的后果是,拥挤的餐馆生意越来越好. 人少的餐馆则长期萧条...
(1) 到陌生都市的游客,驻足街头寻找餐馆时,常常面临这样一个问题: 一家餐馆人满为患,热闹非凡; 隔壁另一家餐馆门可罗雀,只有两三个食客. 在没有其它更多信息的情况下,该到哪家餐馆吃? 如果你像大多数人一样, 答案是: 选择那家人多的餐馆. 因为你没有能力迅速判断哪家餐馆更好,而其他人的选择,成了最可靠的指南. 这种行为模式的后果是,拥挤的餐馆生意越来越好. 人少的餐馆则长期萧条...
(1) 到陌生都市的游客,驻足街头寻找餐馆时,常常面临这样一个问题: 一家餐馆人满为患,热闹非凡; 隔壁另一家餐馆门可罗雀,只有两三个食客. 在没有其它更多信息的情况下,该到哪家餐馆吃? 如果你像大多数人一样, 答案是: 选择那家人多的餐馆. 因为你没有能力迅速判断哪家餐馆更好,而其他人的选择,成了最可靠的指南. 这种行为模式的后果是,拥挤的餐馆生意越来越好. 人少的餐馆则长期萧条...
(1) 到陌生都市的游客,驻足街头寻找餐馆时,常常面临这样一个问题: 一家餐馆人满为患,热闹非凡; 隔壁另一家餐馆门可罗雀,只有两三个食客. 在没有其它更多信息的情况下,该到哪家餐馆吃? 如果你像大多数人一样, 答案是: 选择那家人多的餐馆. 因为你没有能力迅速判断哪家餐馆更好,而其他人的选择,成了最可靠的指南. 这种行为模式的后果是,拥挤的餐馆生意越来越好. 人少的餐馆则长期萧条...
 一个男人,一个非洲男人,一个多年来精心布局全球传媒产业的非洲男人,在微笑. 配图是南非Naspers 集团的前老总,Koos Bekker, 他有四千亿个理由告诉你,为什么视野比勤奋更重要, 为什么长期持有才是王道. Naspers 在2000年时,以三千二百万美元入股腾讯,换来46%左右的股份。(其中一部分股权是从李嘉诚的儿子李泽楷手中买下) 后来历经公司上市,股权增发,其股份降到34%左右。按照三月二十三日腾讯的收盘价145 港元,...
一个男人,一个非洲男人,一个多年来精心布局全球传媒产业的非洲男人,在微笑. 配图是南非Naspers 集团的前老总,Koos Bekker, 他有四千亿个理由告诉你,为什么视野比勤奋更重要, 为什么长期持有才是王道. Naspers 在2000年时,以三千二百万美元入股腾讯,换来46%左右的股份。(其中一部分股权是从李嘉诚的儿子李泽楷手中买下) 后来历经公司上市,股权增发,其股份降到34%左右。按照三月二十三日腾讯的收盘价145 港元,...
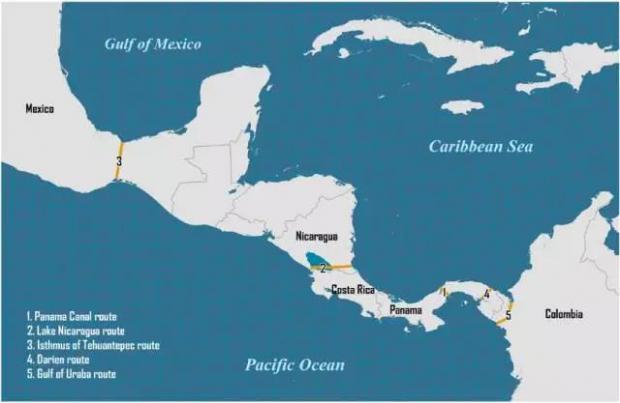 (1) 巴拿马运河,绵延七十七公里,连接大西洋和太平洋,从 1881年开工到1914年才真正建成。运河贯通之后,货船不必再从南美洲的霍恩角绕道,从美国西海岸到东海岸的航程缩短三分之二. 在巴拿马修建运河的想法,十六世纪就有人提出,历经各种探索和曲折,四百年后才实现. 不为多数人所知的是,虽然太平洋在大西洋的西边,但巴拿马运河在太平洋的入海口,Balboa 港口,是在运河的大西洋入海口的东南角。这条路线最...
(1) 巴拿马运河,绵延七十七公里,连接大西洋和太平洋,从 1881年开工到1914年才真正建成。运河贯通之后,货船不必再从南美洲的霍恩角绕道,从美国西海岸到东海岸的航程缩短三分之二. 在巴拿马修建运河的想法,十六世纪就有人提出,历经各种探索和曲折,四百年后才实现. 不为多数人所知的是,虽然太平洋在大西洋的西边,但巴拿马运河在太平洋的入海口,Balboa 港口,是在运河的大西洋入海口的东南角。这条路线最...
 (1) 一九九五年八月九日,创立一年的网景 (Netscape) 在Nasdaq 上市,股价从开盘前的二十八美元,一度日内上涨到七十五美元,收盘时公司市值达到二十九亿美元。网景的创始人 Marc Andreessen, 是最早的互联网浏览器 Mosaic 的开发团队的核心成员之一. 网景的上市,象征着硅谷的互联网革命号角的吹响,其后整个产业的繁荣一直持续到2000年. 投资网景的著名风险资本基金,Kleiner Perkins,一年前以五百万美元的...
(1) 一九九五年八月九日,创立一年的网景 (Netscape) 在Nasdaq 上市,股价从开盘前的二十八美元,一度日内上涨到七十五美元,收盘时公司市值达到二十九亿美元。网景的创始人 Marc Andreessen, 是最早的互联网浏览器 Mosaic 的开发团队的核心成员之一. 网景的上市,象征着硅谷的互联网革命号角的吹响,其后整个产业的繁荣一直持续到2000年. 投资网景的著名风险资本基金,Kleiner Perkins,一年前以五百万美元的...
 ——从寒武纪大爆发和普朗克黑体辐射定律谈起 (1) 笔者曾经提到,随着计算速度的指数型增长,人工智能超过生物人的智能是一个时间上的必然。 但是,未来超级智能,只是简单地提高计算速度和算法,在电脑创造的虚拟空间里意淫一下,就可以实现的了吗? 笔者在未来的几篇系列文章中,将分享一下关于实现超级智能的技术路线图和时间表的看法。 这个话题将非常有争议,我的观点也不一定完全正确,而是会...
——从寒武纪大爆发和普朗克黑体辐射定律谈起 (1) 笔者曾经提到,随着计算速度的指数型增长,人工智能超过生物人的智能是一个时间上的必然。 但是,未来超级智能,只是简单地提高计算速度和算法,在电脑创造的虚拟空间里意淫一下,就可以实现的了吗? 笔者在未来的几篇系列文章中,将分享一下关于实现超级智能的技术路线图和时间表的看法。 这个话题将非常有争议,我的观点也不一定完全正确,而是会...
 (1) 经验, 尤其是失败的经验经历, 对于投资和生活的其它方面都非常有价值. 每当看到一些新人执着地重复我以前犯过的错误,不管他人如何劝说,我只能无奈地笑笑. 经验一:不要去做短线炒股票期货. 绝大部分人在这个博弈中没有任何优势。索罗斯和西蒙斯可能有,但这是例外,大部分人缺乏基本的工具和知识积蓄,最后往往是竹篮打水一场空. 经验二:不要用金融杠杆. 你可能很长时间都有不错的利润, 但只要一...
(1) 经验, 尤其是失败的经验经历, 对于投资和生活的其它方面都非常有价值. 每当看到一些新人执着地重复我以前犯过的错误,不管他人如何劝说,我只能无奈地笑笑. 经验一:不要去做短线炒股票期货. 绝大部分人在这个博弈中没有任何优势。索罗斯和西蒙斯可能有,但这是例外,大部分人缺乏基本的工具和知识积蓄,最后往往是竹篮打水一场空. 经验二:不要用金融杠杆. 你可能很长时间都有不错的利润, 但只要一...
 (1) 投资的策略和回报结果, 是两个不同的概念. 好的策略,短期内不一定回报更好. 不好的策略,或者没有策略 (好比传说中的 "王八拳"),有时因为常常运气,可能回报还不错。这就是所谓 “乱拳打死老师傅”. 金融市场是一个复杂系统,短期价格波动,一半时间可能涨,一半时间可能跌,总有一拨人赚钱。一个人几天, 几个月赚点钱是不难的。难的是十年,二十年,甚至更长的时间段内投资回报超过市场指数. ...
(1) 投资的策略和回报结果, 是两个不同的概念. 好的策略,短期内不一定回报更好. 不好的策略,或者没有策略 (好比传说中的 "王八拳"),有时因为常常运气,可能回报还不错。这就是所谓 “乱拳打死老师傅”. 金融市场是一个复杂系统,短期价格波动,一半时间可能涨,一半时间可能跌,总有一拨人赚钱。一个人几天, 几个月赚点钱是不难的。难的是十年,二十年,甚至更长的时间段内投资回报超过市场指数. ...
 (1) 最近读了一堆关于”复杂系统“的文献书籍, 觉得非常有意思. 复杂系统 (complex system) , 指的是一个系统里, 有多个彼此连接互相作用的元素。 这里的关键词是连接. 如果元素之间没有连接, 就是一个大杂烩, 不属于真正的复杂系统. 公司,组织,国家,生物,金融市场等等,都可以理解为一种复杂系统. (2) 在一个高度互联的复杂系统里,会有很多非线性,很难直觉理解的变化。简单的行为,会导致...
(1) 最近读了一堆关于”复杂系统“的文献书籍, 觉得非常有意思. 复杂系统 (complex system) , 指的是一个系统里, 有多个彼此连接互相作用的元素。 这里的关键词是连接. 如果元素之间没有连接, 就是一个大杂烩, 不属于真正的复杂系统. 公司,组织,国家,生物,金融市场等等,都可以理解为一种复杂系统. (2) 在一个高度互联的复杂系统里,会有很多非线性,很难直觉理解的变化。简单的行为,会导致...
 如果把投资当作一门手艺来看的话,它无疑是世界上最困难的一个学科,它不是上几门课,考一下试就可以真正掌握的. 高学历和投资成功没有直接关联,否则经济学家早就直接下海去发财了. 投资是一个动态的,多方博弈的游戏,其困难在于它充满着各种反人性,反直觉的陷阱. 投资,无处不充满着矛盾. (1) 第一个矛盾是关于简单和复杂. 人们常爱说大道至简,但实际操作上没有那么简单. 在股市上饱受折...
如果把投资当作一门手艺来看的话,它无疑是世界上最困难的一个学科,它不是上几门课,考一下试就可以真正掌握的. 高学历和投资成功没有直接关联,否则经济学家早就直接下海去发财了. 投资是一个动态的,多方博弈的游戏,其困难在于它充满着各种反人性,反直觉的陷阱. 投资,无处不充满着矛盾. (1) 第一个矛盾是关于简单和复杂. 人们常爱说大道至简,但实际操作上没有那么简单. 在股市上饱受折...
 (1) 美国的电力事业公司 (electric utilities) 是一个有趣的物种。大多数人每月支付电费账单,但并不了解电价背后的复杂机制. 巴菲特曾经评论, “电力公司通常是一个必需品的唯一供货商,(监管机构)允许他们调整定价,给他们投入的资本,予以一个事现约定好的回报率。他们不需要效率很高,恰恰相反,业界流传的笑话是,电力事业公司,是世上唯一的生意,如果花钱装修老板的办公室,那么公司就自动赚更多的钱。不少电...
(1) 美国的电力事业公司 (electric utilities) 是一个有趣的物种。大多数人每月支付电费账单,但并不了解电价背后的复杂机制. 巴菲特曾经评论, “电力公司通常是一个必需品的唯一供货商,(监管机构)允许他们调整定价,给他们投入的资本,予以一个事现约定好的回报率。他们不需要效率很高,恰恰相反,业界流传的笑话是,电力事业公司,是世上唯一的生意,如果花钱装修老板的办公室,那么公司就自动赚更多的钱。不少电...
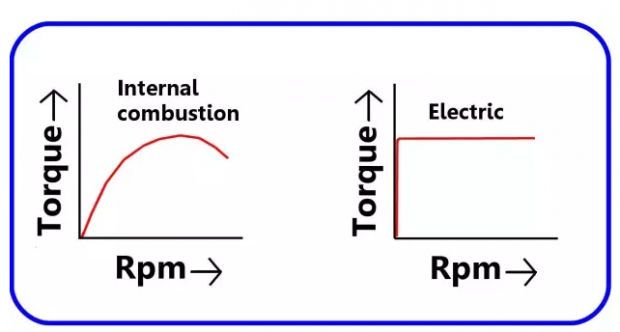 (1) 这里再简单解释一下电车对汽车的一个根本优势. 电动感应马达一通电,马上就可以产生扭矩和推力, 而且无需换挡。汽车的引擎打着火以后,需要从低档一步步换到高档,逐渐提高转速才能提高扭矩和推力。这就是为什么电车加速普遍比汽车快的根本原因。这也是为什么开过电车的人,几乎都不愿意再回去开汽车. 如下图. 特斯拉最高配置 P100D 从 0 到60英里只需要 2.5 秒,这个速度已经超过所有现在生产的汽油车,...
(1) 这里再简单解释一下电车对汽车的一个根本优势. 电动感应马达一通电,马上就可以产生扭矩和推力, 而且无需换挡。汽车的引擎打着火以后,需要从低档一步步换到高档,逐渐提高转速才能提高扭矩和推力。这就是为什么电车加速普遍比汽车快的根本原因。这也是为什么开过电车的人,几乎都不愿意再回去开汽车. 如下图. 特斯拉最高配置 P100D 从 0 到60英里只需要 2.5 秒,这个速度已经超过所有现在生产的汽油车,...
 (1) 第一次出海打渔的人,可能都会有这样的感受:渔船从港湾驶出后,一开始随着海浪轻微起伏,有一种颇为愉悦的失重的快感. 但好景不长,进入深海后,随着波浪起伏的幅度逐渐增大,晕船的感觉慢慢来临,直到突破一个临界点,就开始一发不可收拾的呕吐. 这一刻,我把它叫做 “我靠时刻”. 英文俗称 WTF Moment. (2) 海明威在小说 “太阳照常升起”里曾有这样一段对话: 甲:你是怎么破产的? ...
(1) 第一次出海打渔的人,可能都会有这样的感受:渔船从港湾驶出后,一开始随着海浪轻微起伏,有一种颇为愉悦的失重的快感. 但好景不长,进入深海后,随着波浪起伏的幅度逐渐增大,晕船的感觉慢慢来临,直到突破一个临界点,就开始一发不可收拾的呕吐. 这一刻,我把它叫做 “我靠时刻”. 英文俗称 WTF Moment. (2) 海明威在小说 “太阳照常升起”里曾有这样一段对话: 甲:你是怎么破产的? ...

(1)
Deepmind 的 DQN 在 Atari 的七个不同的游戏 (Beam Rider, Breakout, Enduro, Pong, Q*bert, Seaquest, Space Invaders) 中,有六个游戏的最高得分都超过了人类的最好玩家.
最出乎人们意料的是程序在 Breakout (突围)游戏中的表现.
刚开始, 不了解游戏规则的程序,表现得像个无头苍蝇,老是漏球.
经过10分钟的训练后,慢慢懂得要用板子击球,才可以得分.
经过120分钟的训练后,程序可以迅速准确击球,表现得有...

(1)
游戏公司 Atari 在1977年推出的 Breakout (突围)电脑游戏,主要开发者是苹果公司的创始人之一, Steve Wozniak. 乔布斯的角色是 Atari 和 Wozniak 中间的掮客.
Atari 起先告诉乔布斯,游戏如果四天内开发出来,将支付 700 美元的报酬。乔布斯许诺和 Wozniak 平分这笔钱。但Wozniak 不知道的是, Atari 还承诺如果此游戏在逻辑芯片的需求上低于某个指标,将给予更多的奖励.
最终Wozniak 连续四天挑灯夜战只拿到了 3...

(1)
在增强学习领域,经历 (experience) 是指四个参数的集合, (x, a, y, r) 表示在状态 x, 做了 a, 进入了新的状态 y, 获得了回报 r. 教训 (lesson) 则是指一个时间序列的经历的集合.
经历回放 (experience replay) 的概念由 Long Ji Lin 在 1993年的博士论文里第一次提出.
"经历回放" 的第一个好处是更有效率。经验教训,尤其是有重大损失的经验教训,是昂贵的,如果把它存储到记忆里,可以日后反复调用学习,那么学习效...
(1)
在用神经网络计算拟合最优价值函数 (最大利益)的实践中,最大的挑战,就是神经网络的参数无法收敛到最优值,无法求解. 换句话说,神经网络的参数变得发散 (Divergent).
传统的‘发散思维’一词,指某人思维活跃有想象力. 但是神经网络的参数发散,在这里就对应于大脑无所适从,精神错乱了。
这个问题的第一个原因是, 增强学习在和环境互动的过程中, 获得的数据都是高度相关的连续数列。当神经网络依靠这些数据来优化...

(1)
所有没有成熟的新理论,新技术出现之初,学术界都会有两派:
好派 (人工智能,增强学习就是好, 就是好!)
和
P 派 (人工智能,增强学习好个 P, 好个 P ! )
P 派对增强学习理论最为诟病之处:不实用,然并卵.
迄今为止关于各种算法的讨论,都离不开一个核心概念: 价值函数.
简单说,在贝尔曼方程里面,价值函数就是目前状态的理论最大值。(参见这篇老文章 王川: 深度学习有多深? (十九) -- 维度的诅咒和蒙...
(1)
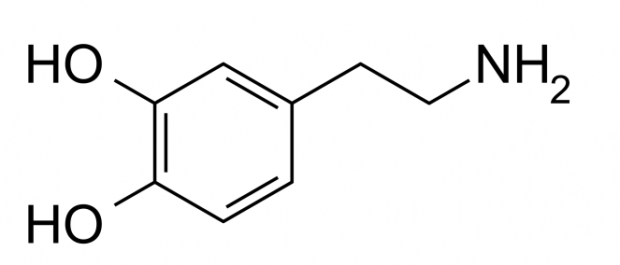
多巴胺,英文名 Dopamine, 是一种有机化合物, 学名 4-(2-Aminoethyl)benzene-1,2-diol, 4-(2-氨基乙基)-1,2-苯二酚, 在大脑中它的作用是在神经元之间传递信号的介质.
多巴胺作为神经介质 (neurotransmitter)的功能, 最早在1957年由瑞典化学家 Arvid Carlsson 发现, Carlsson 四十三年之后才因此发现获得诺贝尔奖.
多巴胺对于人脑的运作至关重要. 在普通人的印象中,多巴胺的释放是和食物,烟酒,性快感或者毒品联系在一...
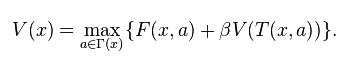
(1)
动态规划理论的核心, 用以 Richard Bellman 老师名字命名的 贝尔曼方程 (Bellman Equation)表示.
贝尔曼方程的核心, 就是:
用大白话说, 就是
目前状态的最大价值 = 最大化[ 眼前的回报 + {未来的最大价值,贴现到现在} ]
而动态规划要解决的问题,无非就是求解方程里的最优价值函数 V(x) 而已.
使用贪婪算法的人们,只专注"眼前的回报",而忽略了"对未来最大价值贴现到现在"的认真计算.
社会上对部...

(1)
迄今为止我们讨论的人工智能的问题,都还是局限在"认知"方面的应用, 比如图像识别,语音识别,自然语言处理,等等.
这类问题的特点是,机器获得大量原始数据的培训. 每一个输入,都有标准的"输出"的答案. 这种学习方式,也称为"有监督学习".
但是生活中大多数问题,是没有标准正确答案的.你的所作所为,偶尔会得到一些时而清晰, 时而模糊的反馈信号. 这就是"增强学习" (Reinforcement Learning) 要解决的问题.
"增强学习"的...